
Wie Du eine Solo-Produktion mit Auphonic startest, haben wir in Lektion 2 besprochen. Heute soll es um Multitrack-Produktionen gehen. Das funktioniert im Wesentlichen exakt genau so, bringt aber entscheidende Vorteile, wenn Du mit mehreren Leuten gemeinsam podcastest. Ich gehe in dieser Lektion davon aus, dass Du einen Auphonic-Account hast und dass Du grundsätzlch weiß, wie Auphonic funktioniert. Für die Grundeinstellungen lies bitte noch einmal die Lektionen 1 und 2 dieses Tutorials in Ruhe durch.
Was genau ist eine „Multitrack-Produktion“?
„Multitrack“ bedeutet, dass es für eine Produktion mehrere Tonspuren gibt. Das wäre zum Beispiel der Fall, wenn Du eine oder mehrere Personen zu Gast in Deinem Podcast hast oder wenn Du O-Töne, Geräusche oder Musik einspielen möchtest. Wie schon in meinem Artikel Eine Podcastepisode aufnehmen und nachbearbeiten erklärt, möchtest Du für jede Sprecherin ein eigenes Mikrofon benutzen. In Deiner Schnittsoftware sollte dann analog dazu für jedes Mikrofon (genauer: für jedes Eingangssignal, also auch zugespielte O-Töne etc) eine eigene Tonspur auftauchen. Hier mal ein Beispiel für den Haialarm-Podcast:
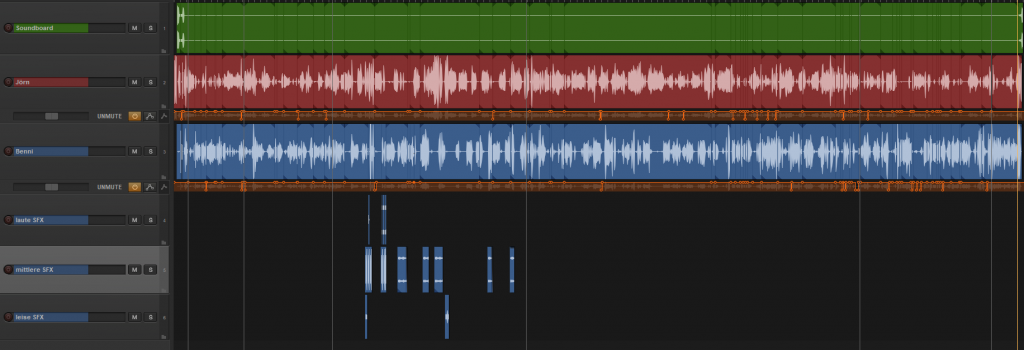
Von oben nach unten siehst Du hier Spuren für das Soundboard von dem wir das Intro und das Outro sowie O-Töne zuspielen, falls wir denn die Genehmigung dafür bekommen. Darunter sind die Tonspuren von Benni und mir mit den zugehörigen Mute-Spuren. Darunter siehst Du drei Spuren für Geräuscheffekte, die ich unter nachgestellte Szenen mische.
Wenn ich all das fertig habe, also die Sprache geschnitten und die Soundeffekte eingebaut sind und ich die Kapitelmarken platziert habe, exportiere ich jede dieser Tonspuren als eigene Datei und lege sie in meine Dropbox. So kann Auphonic später beim Mastering alle Spuren für sich allein bearbeiten, „sieht“ dabei aber das gewünschte Gesamtergebnis. Am Ende bekomme ich ein besseres Ergebnis, als wenn ich alle Spuren in eine Datei zusammenmische und die dann durch Auphonic bearbeiten lasse.
Wichtig: Alle Dateien müssen zum gleichen Zeitpunkt beginnen. Das klingt trivial, ist es aber nicht. Wenn Du mal das Bild oben ansiehst, wirst Du bemerken, dass in der obersten, der grünen Spur ganz links ein Ausschlag ist und dann eine lange, flache Linie (Stille) folgt. Andererseits ist es bei den Soundeffekten: Die schweben einfach in der Spur herum, davor ist einfach nichts – noch nicht einmal Stille. Hier gibt es große Unterschiede zwischen den einzelnen Schnittsoftwares. Bei Audacity beginnt die Spur des Soundeffekts beim ersten Geräusch, also in diesem Fall bei etwa 15’24“. Das Geräusch würde in diesem Fall ganz am Anfang der fertigen Auphonic-Produktion auftauchen. Reaper bzw. Ultraschall fügt automatisch 15 min und 24 Sekunden Stille ein. Zur Not musst Du per Hand am Anfang etwas Stille einfügen, damit die Dateien alle synchron laufen.
Workflow bei Auphonic
Bei Auphonic klicke ich nun auf „Multitrack-Produktion starten“ und gehe im Prinzip die gleichen Arbeitsschritte durch, die ich auch schon bei der Solo-Produktion hatte: Der Unterschied ist nur, dass ich mehr als eine Datei hochlade, im Fall des Haialarm-Podcasts halt sechs Stück. Aber auch das Interface sieht ein wenig anders aus:

Für jede Datei kannst Du nun festlegen, ob und wenn ja welche Filter darauf angewendet werden sollen. „Filtering“ ist ein Hochbandfilter, der einige Störgeräusche herausfiltert. Die „Noise and Hum Reduction“ soll störende Hintergrundgeräusche und Netzbrummen erkennen und herausfiltern. Es ist sinnvoll beide Optionen zu aktivieren. Wenn Du sicher sein möchtest, dass die lebhafte Atmosphäre im Park oder auf einem belebten Platz erhalten bleibt, solltest Du die „Noise and Hum Reduction“ ausschalten.
Zu guter Letzt kannst Du für jede Spur festlegen, ob sie im Vorder- oder Hintergrund spielt. Es gibt noch mehr Optionen, aber bleiben wir erstmal bei diesen beiden. Sprecherinnen sollten immer im Vordergrund platziert sein, Musik und Geräuscheffekte in der Regel im Hintergrund. Den Unterschied zwischen Sprache und Musik erkennt Auphonic recht zuverlässig, hier kannst Du prinzipiell auch die Einstellung auf „Auto“ belassen. Ich mache das lieber manuell, mein innerer Monk zwingt mich dazu.
Ein Track der auf „Background“, also Hintergrund, eingestellt ist, wird immer um -18 dbA leiser sein, als die Vordergrundspuren. Und Du kannst für eine Spur auch „Duck this track“ einschalten. Dann wird die Lautstärke dieses Tracks in dem Moment um -18 dbA reduziert, in dem auf einem Vordergrund-Track gesprochen wird.
Als letzte Option gibt es auch noch „Unchanged (Foreground)“. Dafür habe ich für mich noch keine sinnvolle Verwendung gefunden. Diese Option besagt lediglich, dass das Lautstärkeverhältnis zu den Vordergrundspuren nicht verändert wird. Trotzdem werden hier leise Passagen im Audio auf das gleiche Lautstärkeniveau angehoben wie die lauten Passagen in dieser Datei.
Die restlichen Einstellungen für Intro und Outro, Metadaten und Kapitelmarken sind die gleichen wie bei einer Solo-Produktion. Deine Export-Services kannst Du hier genau so nutzen.
Bevor Du aber auf „Start Production“ klicken kannst, bietet Auphonic Dir noch einige wichtige Einstellungsmöglicheiten:
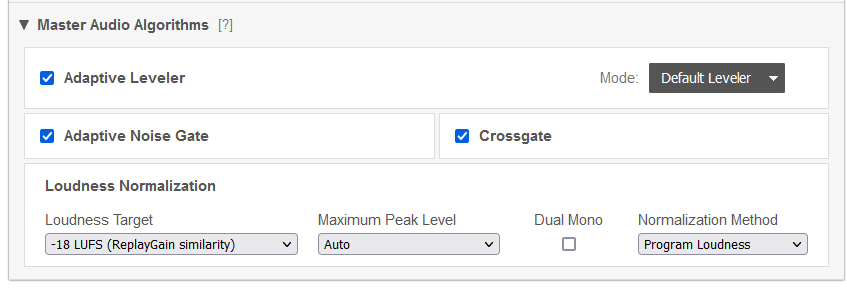
Sehr cool finde ich den „Adaptive Leveler“, der Lautstärkeunterschiede zwischen den Sprecherinnenspuren ausgleicht und dafür sorgt, dass alle Beteiligten gleich laut abgemischt werden. Kurz: Du möchtest das.
Das „Adaptive Noise Gate“ regelt die Lautstärke einer Tonspur herunter, wenn dort gerade nicht gesprochen wird. Das verringert Störgeräusche zusätzlich.
„Crossgate“ ist dann relevant, wenn Ihr für die Aufnahme alle in einem Raum gesessen habt. Üblicherweise nehmen alle Mikrofone immer alle Sprecherinnen im Raum auf. Heißt: Wenn ich gerade still bin und meine Gesprächspartnerin spricht, wird ein kleines bisschen ihrer Stimme auch auf meiner Spur sein. Das Crossgate erkennt das und blendet diese Passagen aus. Im Ergebnis klingt meine Gesprächspartnerin viel trockener und präsenter.
Beim Loudness-Target (Lautheit) scheiden sich ein wenig die Geister. In Podcasterinnenkreisen hat sich ein Loudness-Target von -16 LUFS eingebürgert, Sendestandard in den Sendern der European Broadcasting Union (die z.B. auch den Eurovision Song Contest ausstrahlt) ist -24 LUFS. Ich wiederum backe meine eigenen Brötchen: -16 ist mir oft zu laut, -24 ist für mich vielen Situationen zu leise. Deswegen setze ich diesen Wert auf -18 und bin damit ganz zufrieden. Die weiteren Einstellungen kannst Du getrost auf dem voreingestellten Wert belassen.